 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks are Not Enough: RAMP for Runtime Assessing of Agentic Models in Production Systems
May 26, 2026LLM agents are rapidly evolving from coding assistants into autonomous software engineering systems. However, existing evaluation methodologies remain largely centered on static, isolated, and short-horizon benchmarks that fail to capture the dynamic complexity of real-world production workflows. As a result, benchmark performance may poorly reflect practical capability under realistic runtime environments involving long execution chains, tool interactions, dependency management, and iterative feedback loops. We thus present RAMP, a production-grounded infrastructure for assessing long-horizon software engineering agents. Built upon the YatCC integrated platform, RAMP provides a unified runtime assessment architecture through standardized orchestration and execution interfaces. RAMP introduces realistic compiler-construction workloads with serial dependencies and complex toolchain interactions, together with a staged recovery mechanism for analyzing execution behavior under partial workflow failure. The framework further incorporates utility-oriented multi-dimensional metrics that jointly evaluate outcome quality and process efficiency. We conduct runtime assessments across 15 mainstream models and observe substantial capability degradation that remains largely invisible to conventional isolated benchmarks. Task completion rates progressively collapse across serial workflows, dropping from 100% in the initial stage to only 20% in the final stage, while none of the evaluated models successfully completes the entire pipeline. Runtime analysis reveals systematic failure propagation and significant resource inefficiencies, with computational costs differing by up to three orders of magnitude among comparable models. These findings suggest RAMP advances agentic model evaluation toward continuous, runtime-observable, and production-grounded assessment.
StepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents
May 05, 2026LLM-Agents have evolved into autonomous systems for complex task execution, with the SKILL.md specification emerging as a de facto standard for encapsulating agent capabilities. However, a critical bottleneck remains: different agent frameworks exhibit starkly different sensitivities to prompt formatting, causing up to 40% performance variation, yet nearly all skills exist as a single, format-agnostic Markdown version. Manual per-platform rewriting creates an unsustainable maintenance burden, while prior audits have found that over one third of community skills contain security vulnerabilities. To address this, we present SkCC, a compilation framework that introduces classical compiler design into agent skill development. At its core, SkIR - a strongly-typed intermediate representation - decouples skill semantics from platform-specific formatting, enabling portable deployment across heterogeneous agent frameworks. Around this IR, a compile-time Analyzer enforces security constraints via Anti-Skill Injection before deployment. Through a four-phase pipeline, SkCC reduces adaptation complexity from $O(m \times n)$ to $O(m + n)$. Experiments on SkillsBench demonstrate that compiled skills consistently outperform their original counterparts, improving pass rates from 21.1% to 33.3% on Claude Code and from 35.1% to 48.7% on Kimi CLI, while achieving sub-10ms compilation latency, a 94.8% proactive security trigger rate, and 10-46% runtime token savings across platforms.
EFIM: Efficient Serving of LLMs for Infilling Tasks with Improved KV Cache Reuse
May 29, 2025Large language models (LLMs) are often used for infilling tasks, which involve predicting or generating missing information in a given text. These tasks typically require multiple interactions with similar context. To reduce the computation of repeated historical tokens, cross-request key-value (KV) cache reuse, a technique that stores and reuses intermediate computations, has become a crucial method in multi-round interactive services. However, in infilling tasks, the KV cache reuse is often hindered by the structure of the prompt format, which typically consists of a prefix and suffix relative to the insertion point. Specifically, the KV cache of the prefix or suffix part is frequently invalidated as the other part (suffix or prefix) is incrementally generated. To address the issue, we propose EFIM, a transformed prompt format of FIM to unleash the performance potential of KV cache reuse. Although the transformed prompt can solve the inefficiency, it exposes subtoken generation problems in current LLMs, where they have difficulty generating partial words accurately. Therefore, we introduce a fragment tokenization training method which splits text into multiple fragments before tokenization during data processing. Experiments on two representative LLMs show that LLM serving with EFIM can lower the latency by 52% and improve the throughput by 98% while maintaining the original infilling capability. EFIM's source code is publicly available at https://github.com/gty111/EFIM.
VecTrans: LLM Transformation Framework for Better Auto-vectorization on High-performance CPU
Mar 25, 2025Large language models (LLMs) have demonstrated great capabilities in code generation, yet their effective application in compiler optimizations remains an open challenge due to issues such as hallucinations and a lack of domain-specific reasoning. Vectorization, a crucial optimization for enhancing code performance, often fails because of the compiler's inability to recognize complex code patterns, which commonly require extensive empirical expertise. LLMs, with their ability to capture intricate patterns, thus providing a promising solution to this challenge. This paper presents VecTrans, a novel framework that leverages LLMs to enhance compiler-based code vectorization. VecTrans first employs compiler analysis to identify potentially vectorizable code regions. It then utilizes an LLM to refactor these regions into patterns that are more amenable to the compiler's auto-vectorization. To ensure semantic correctness, VecTrans further integrates a hybrid validation mechanism at the intermediate representation (IR) level. With the above efforts, VecTrans combines the adaptability of LLMs with the precision of compiler vectorization, thereby effectively opening up the vectorization opportunities. Experimental results show that among all 50 TSVC functions unvectorizable by Clang, GCC, and BiShengCompiler, VecTrans successfully vectorizes 23 cases (46%) and achieves an average speedup of 2.02x, greatly surpassing state-of-the-art performance.
THUEE system description for NIST 2019 SRE CTS Challenge
Dec 25, 2019
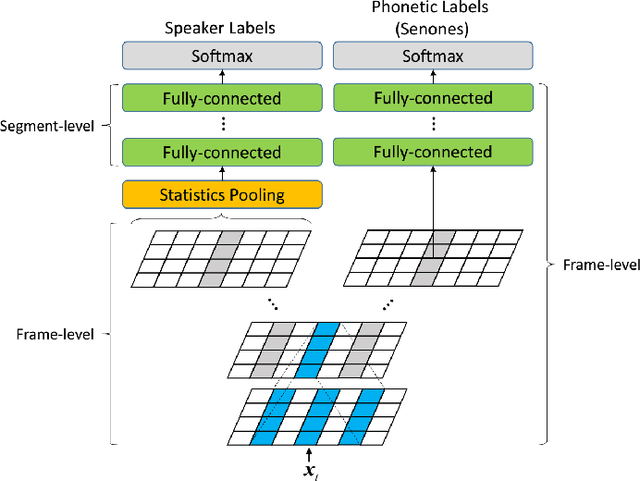
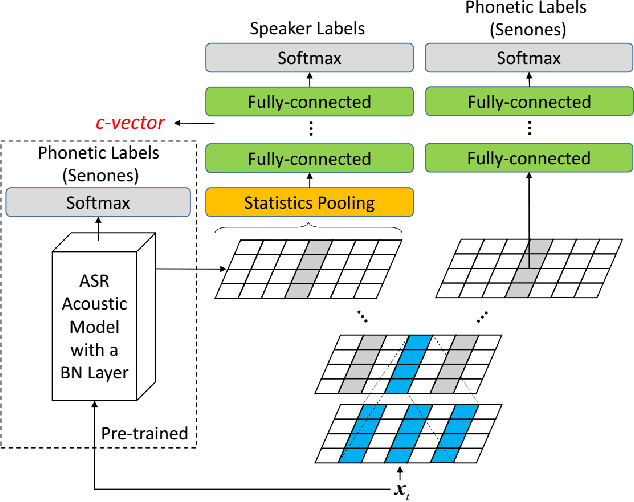

This paper describes the systems submitted by the department of electronic engineering, institute of microelectronics of Tsinghua university and TsingMicro Co. Ltd. (THUEE) to the NIST 2019 speaker recognition evaluation CTS challenge. Six subsystems, including etdnn/ams, ftdnn/as, eftdnn/ams, resnet, multitask and c-vector are developed in this evaluation.